MySQL表分区的实验
MySQL自带一项表分区的功能,可以将一张表的表文件拆分为多个文件,提高大表的IO效率,最近做了一些实验,验证了一下表分区的可用性
MySQL官方文档:
关于分区的全面介绍
分区键的约束,看了很多网上的文章没看懂,看了官方的解释才明白是怎么回事
什么是MySQL表分区
mysql数据库中的数据是以文件的形式存在磁盘上的,一张表主要对应着两个个文件,一个是frm存放表结构的,一个是ibd存放表数据和索引的。如果一张表的数据量太大的话,那么idb就会变的很大,查找数据就会变的很慢,这个时候我们可以利用mysql的分区功能,在物理上将这一张表对应的两个个文件,分割成许多个小块,这样呢,我们查找一条数据时,就不用全部查找了,只要知道这条数据在哪一块,然后在那一块找就行了。如果表的数据太大,可能一个磁盘放不下,这个时候,我们可以把数据分配到不同的磁盘里面去。
MySQL表分区实验
我首先根据mysql的表分区功能创建了两个实验表,结构一样,只是一个表分区,另一个不分区。
不分区的表tbl_test_nosub:
CREATE TABLE `tbl_test_nosub` (
`fld_record_id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '记录号',
`fld_create_time` timestamp(0) NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间(local_time)',
`fld_modif_time` timestamp(0) NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '最后修改时间',
`fld_deleted` tinyint(4) NOT NULL DEFAULT 0 COMMENT '删除标记(非0表示已经删除了)',
`fld_value_str` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '',
`fld_value_int` int(255) NOT NULL DEFAULT 0,
`fld_value_key` int(255) NOT NULL DEFAULT 0,
PRIMARY KEY (`fld_record_id`) USING BTREE,
INDEX `idx_key`(`fld_value_key`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = Compact;
分区的表tbl_test_sub:
CREATE TABLE `tbl_test_sub` (
`fld_record_id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '记录号',
`fld_create_time` timestamp(0) NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间(local_time)',
`fld_modif_time` timestamp(0) NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '最后修改时间',
`fld_deleted` tinyint(4) NOT NULL DEFAULT 0 COMMENT '删除标记(非0表示已经删除了)',
`fld_value_str` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '',
`fld_value_int` int(255) NOT NULL DEFAULT 0,
`fld_value_key` int(255) NOT NULL DEFAULT 0,
PRIMARY KEY (`fld_record_id`) USING BTREE,
INDEX `idx_key`(`fld_value_key`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = Compact PARTITION BY HASH (fld_record_id)
PARTITIONS 4
(PARTITION `p0` MAX_ROWS = 0 MIN_ROWS = 0 ,
PARTITION `p1` MAX_ROWS = 0 MIN_ROWS = 0 ,
PARTITION `p2` MAX_ROWS = 0 MIN_ROWS = 0 ,
PARTITION `p3` MAX_ROWS = 0 MIN_ROWS = 0);
通过对两张表插入同样的递增数据5000万条来测试查询效率,用我自己写的python脚本分别对两张表查询1万次,tbl_test_sub耗时8秒左右,而tbl_test_nosub耗时5秒左右。
"SELECT * FROM `%s` WHERE `fld_record_id` = %d;" (fld_record_id随机1到5000w)
按照mysql官方的文档,表分区后,这种简单的唯一条件查询(而且条件是主键)应该会触发所谓的分区修剪,只查询相对应的分区,减少查询时间。可是在我的测试中分区表的查询速度反而降低了。
尝试重建了分区,将分区数量加大:
Alter table tbl_test_sub partition by key(fld_record_id) partitions 24; //重建分区表大概花费了700秒
然后尝试用python脚本分别对两张表查询10万次,tbl_test_sub耗时87s左右,而tbl_test_nosub耗时81s左右。分区后的表查询速度还是慢的。
为了减少python本身对mysql效率的影响,我又改为用存储过程来测试查询效率:
DROP PROCEDURE IF EXISTS test_select;
DELIMITER &&
CREATE PROCEDURE load_part()
BEGIN
DECLARE i INT;
SET i=1;
WHILE i<100000
DO
SELECT * FROM tbl_test_sub WHERE fld_record_id = i*100;
SET i=i+1;
END WHILE;
END&&
DELIMITER ;
CALL test_select;
我的python脚本每次查询的条件 fld_record_id 都是随机的,想在存储过程中也使用这种方法,但是不知为何mysql自己的RAND()函数执行效率非常差,执行一次需要30s,所以改为定数查询,这样应该也更客观一点。可能由于innodb缓存的作用,每查询一次速度就会快一些,三四次之后查询时间会稳定在一个值,tbl_test_sub五次查询的时间分别是 36s,37s,22s,24s,22s、tbl_test_nosub五次查询的时间分别是 31s,32s,21s,21s,21s。差别并不是很大,但是分区之后的查询还是慢一些。如果把条件从fld_record_id分区键更换为普通索引fld_value_key的话,tbl_test_sub五次查询的时间分别是 51s,43s,42s,42s,42s、tbl_test_nosub五次查询的时间分别是 51s,27s,25s,25s,25s。可以看到差距还是非常大的,因为分区键首先进行了分区定位,进行了分区修剪,只会在数据存在的分区内进行查找,而非分区键数据列虽然也做了索引,但是不能定位分区,最坏的情况下会在所有的分区中进行查找。通过explain的结果可以证实这一点:
EXPLAIN PARTITIONS SELECT * FROM tbl_test_sub WHERE fld_value_key = 1;
EXPLAIN PARTITIONS SELECT * FROM tbl_test_nosub WHERE fld_value_key = 1;
EXPLAIN PARTITIONS SELECT * FROM tbl_test_nosub WHERE fld_record_id = 1;
EXPLAIN PARTITIONS SELECT * FROM tbl_test_sub WHERE fld_record_id = 1;
MySQL官方文档中关于表分区的优点是这样说的(来源于https://dev.mysql.com/doc/refman/5.6/en/partitioning-overview.html):
1,表分区功能可以使一张表中存储的数据比单个磁盘或文件系统分区中存储的数据更多。
2,通过删除仅包含该数据的一个或多个分区,通常可以轻松地从分区表中删除失去其用途的数据。相反,在某些情况下,通过添加一个或多个用于专门存储该数据的新分区,可以大大简化添加新数据的过程。
3,满足以下条件的某些查询可以大大优化:满足给定WHERE子句的数据只能存储在一个或多个分区上,这会自动从搜索中排除任何剩余的分区。由于可以在创建分区表之后更改分区,因此您可以重新组织数据以增强在首次设置分区方案时可能不会经常使用的频繁查询。排除不匹配分区(以及因此包含的任何行)的能力通常称为分区修剪。
关于查询效率的解释上,我的实验应该符合官方的说法,但是并没有提高查询效率,可能是数据文件拆分后从小块文件中查询得到的效率提升并没有定位分区消耗的效率大。据说一颗3层的B+树可以承载的数据是2000W,超过2000W应该会增加到4层,但是通过查询MySQL的数据我的实验数据表已经达到了5000W条,依然是3层:
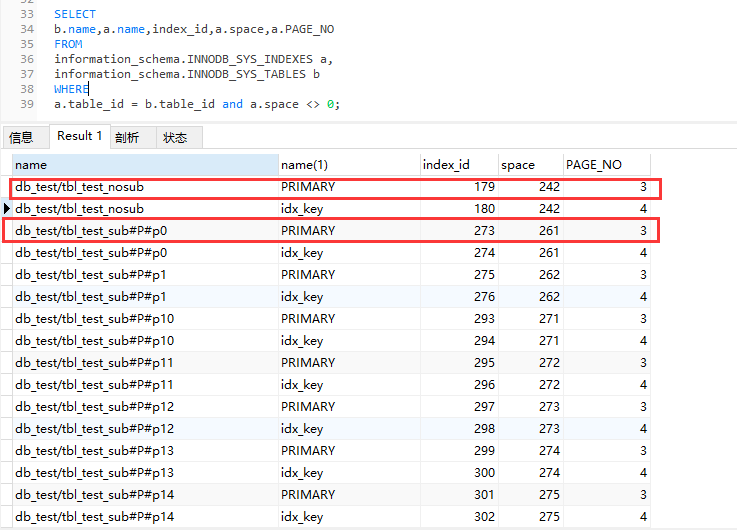
SELECT
b.name,a.name,index_id,a.space,a.PAGE_NO
FROM
information_schema.INNODB_SYS_INDEXES a,
information_schema.INNODB_SYS_TABLES b
WHERE
a.table_id = b.table_id and a.space <> 0;
使用innodb_space查看数据表所在页面的B+树高度(innodb_space在centos6上如何安装):
# innodb_space -f ./tbl_test_nosub.ibd space-index-pages-summary | head -n 10
page index level data free records
3 179 2 3298 12860 194
4 180 2 2100 14122 100
5 179 0 7680 8496 152
6 179 0 15047 1067 293
7 179 0 15037 1077 292
8 179 0 15077 1037 292
9 180 0 15283 521 899
10 180 0 15283 521 899
11 179 0 309 15943 6
# innodb_space -f ./tbl_test_sub#P#p0.ibd space-index-pages-summary | head -n 10
page index level data free records
3 273 2 289 15959 17
4 274 2 168 16082 8
5 273 0 16011 125 310
6 273 0 9424 6760 182
7 273 0 13832 2322 267
8 273 0 9423 6749 182
9 274 0 9010 7054 530
10 274 0 13685 2285 805
11 273 0 6625 9579 128
page_no为3和4的page_level是2,因为根level是0,所以这个树高度是3层;
所以在我的实验中,5000W的数据表虽然进行了分区,但是B+树的层数依然是3层,在IO次数上没有变化,所以IO上提升的效率基本没有,但是由于定位分区需要开销,所以总体来说查询效率是下降的。我的结论是,也许数据量超过一定数量级后B+树会变为4层,这样一次分区表的查询会减少一次IO操作,也许会大于定位分区带来的开销,这样总体查询效率可能有提升。但是表分区总体解决的是表容量的问题,适合按时间分区,比如按不同年份分区来区分热点数据和非热点数据。