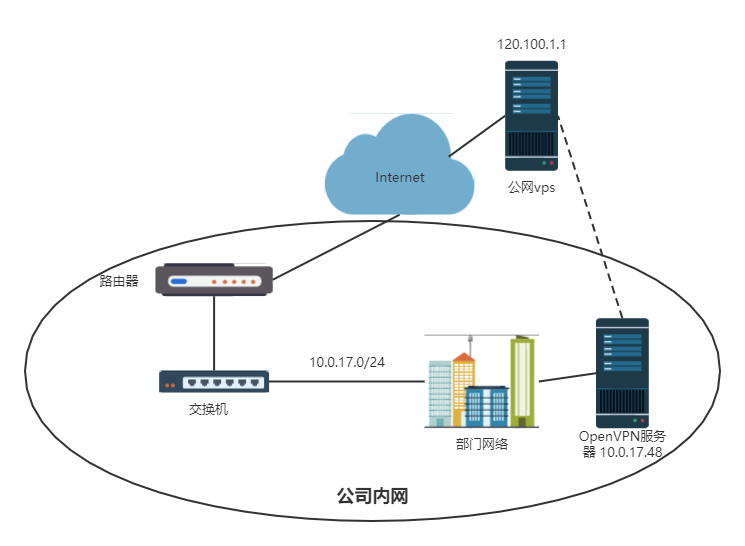
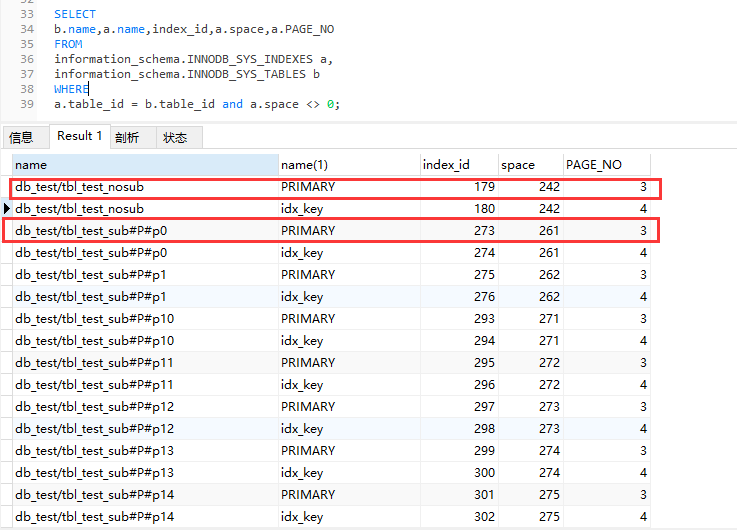
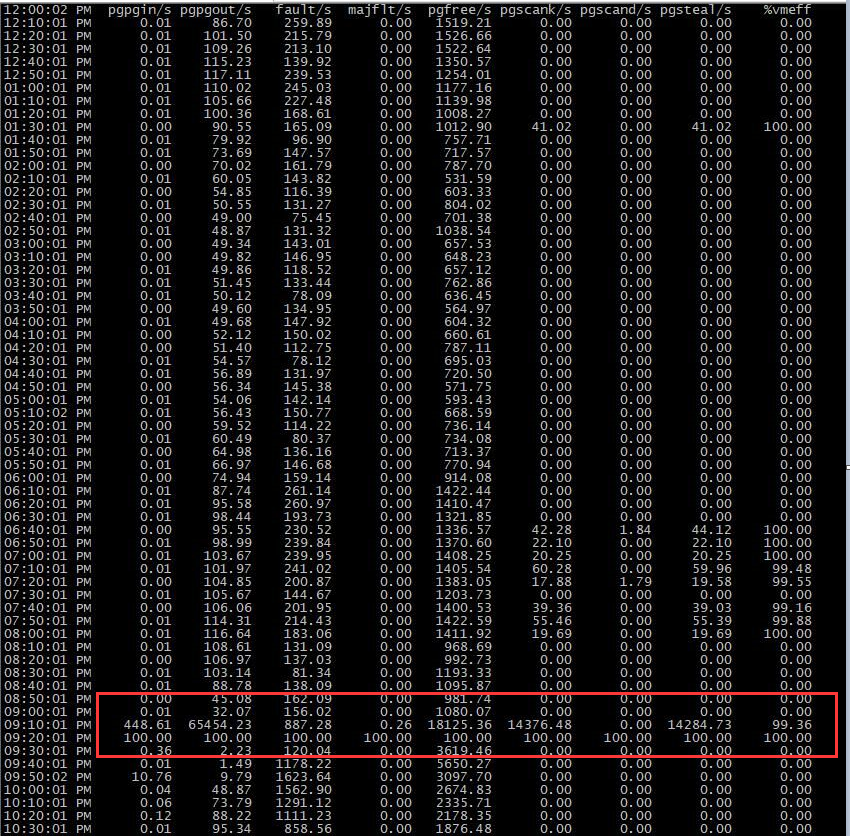
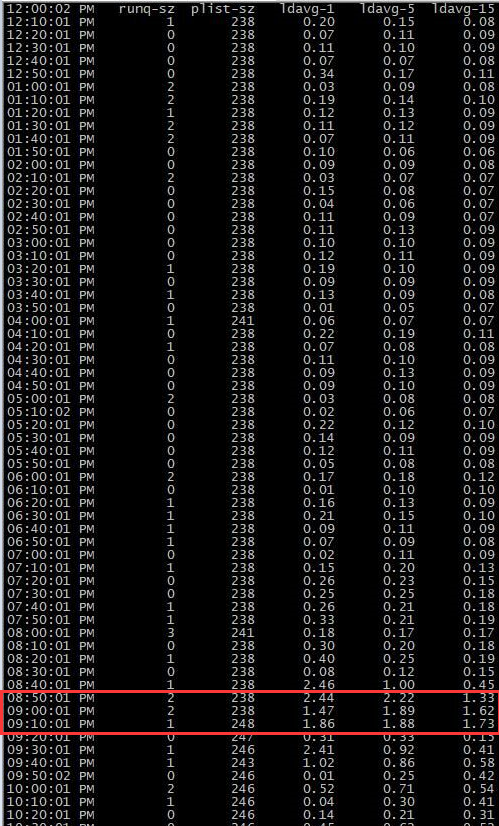
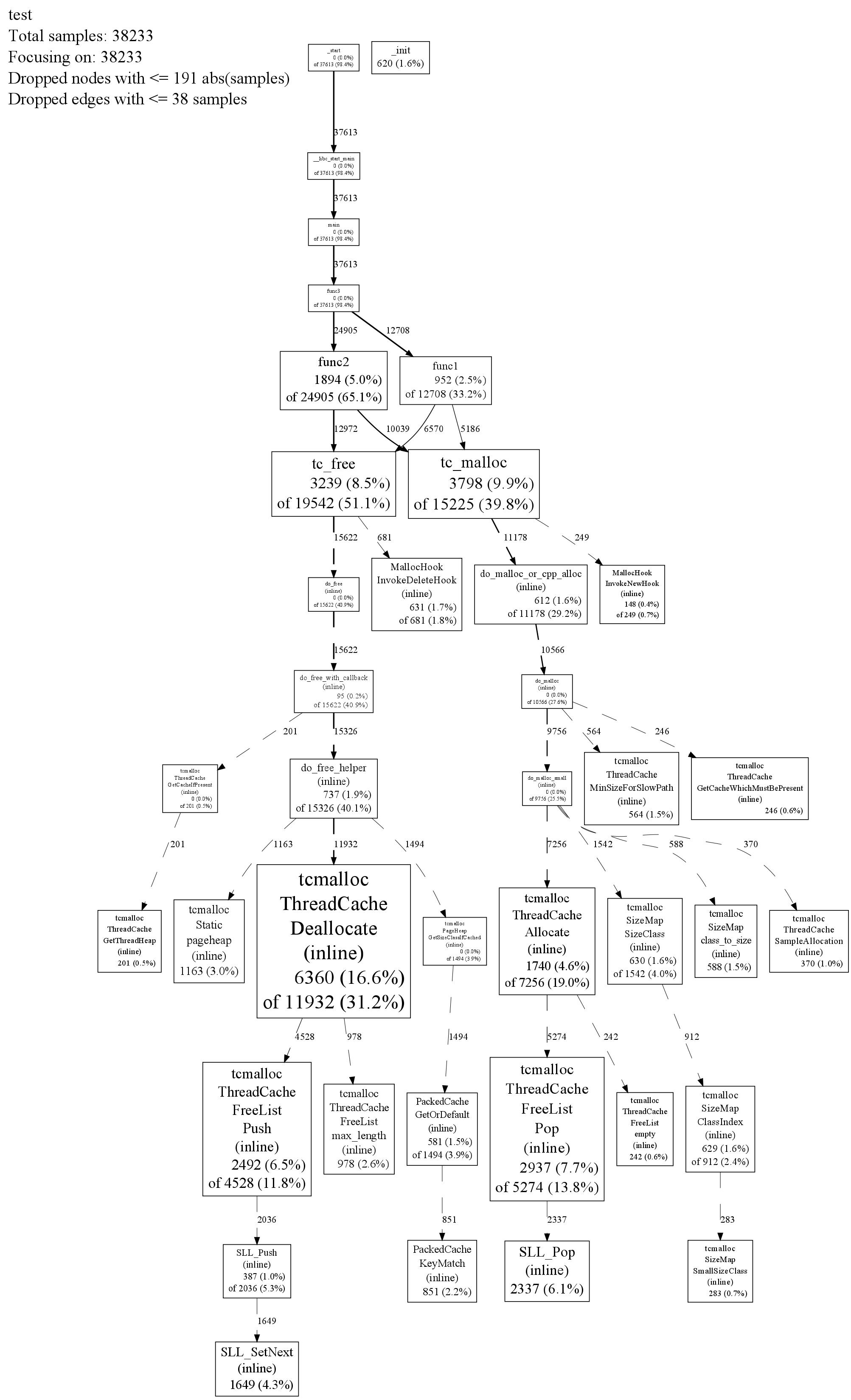
#头文件#
//tetris.h
#ifndef _TETRIS_H_
#define _TETRIS_H_
//#define _TETRIS_DEBUG
#include "include/glut.h"
#include "include/glpng.h"
#include <list>
#pragma comment(lib,"glpng.lib")
#define TETRIS_SCALE 2
#define TETRIS_SCREEN_WIDTH ((GLint)(96*TETRIS_SCALE))
#define TETRIS_SCREEN_HEIGHT ((GLint)(192*TETRIS_SCALE))
#define TETRIS_INFO_WIDTH 120
#define TETRIS_KEY_ESCAPE 27
#define TETRIS_KEY_UP 72
#define TETRIS_KEY_DOWN 80
#define TETRIS_KEY_LEFT 75
#define TETRIS_KEY_RIGHT 77
#define TETRIS_KEY_SPACE 32
#define TETRIS_KEY_ENTER 13
#define TETRIS_TEXTURE_COUNT 4
#define TETRIS_UNIT_WIDTH 32
#define TETRIS_UNIT_HEIGHT 32
#define TETRIS_COLOR_BLUE 0
#define TETRIS_GREEN_BLUE 1
#define TETRIS_RED_BLUE 2
#define TETRIS_YELLOW_BLUE 3
#define TETRIS_UNITS_NUM (TETRIS_SCREEN_WIDTH/TETRIS_UNIT_WIDTH*TETRIS_SCREEN_HEIGHT/TETRIS_UNIT_HEIGHT)//72
#define TETRIS_COL_NUMS (TETRIS_SCREEN_WIDTH/TETRIS_UNIT_WIDTH)//6
#define TETRIS_ROW_NUMS (TETRIS_SCREEN_HEIGHT/TETRIS_UNIT_HEIGHT)//12
#define TETRIS_FREQUENCY_MAX 32
#define TETRIS_FREQUENCY_MIN 1
#define TETRIS_DELAY_TIME 100
using namespace std
struct ImageRec {
unsigned long sizeX
unsigned long sizeY
char *data
}
typedef struct _unitData{
GLubyte angle:2,color:2,fill:2,stat:2
}unitData
typedef struct{
GLshort col,row
}unitPos
typedef struct
{
GLint mainWindow
GLint textureCount
GLuint theTextures[TETRIS_TEXTURE_COUNT+1]
unitData units[TETRIS_UNITS_NUM+TETRIS_COL_NUMS*2]
unitData CurUnits[2]
unitPos CurUnitsPos[2]
GLint CurUnitsStat
GLint frequency
GLint frequencymax
GLint score
GLint scoreLastLevel
GLint level
GLint gamecount
GLboolean gameover
GLboolean gamepause
GLboolean updating
list<unitData*> pool
list<unitData*> poolex
GLint fontBase
GLboolean levelStart
GLint delay
GLint updateLevel
GLint waitUserTextSy,waitUserTextSydir
}tetrisMainData
#endif
#源文件#
#include "tetris.h"
//////////////////////////////////////////////////////////////////////////
//////////////////////////////////////////////////////////////////////////
using namespace std
const char *appName="Tetris"
const char *texturefiles[]={
"puyo_blue.png",
"puyo_green.png",
"puyo_red.png",
"puyo_yellow.png",
}
const GLint TexCoord[4][4][2]={
0.0,0.0, 1.0,0.0, 1.0,1.0, 0.0,1.0,
0.0,1.0, 0.0,0.0, 1.0,0.0, 1.0,1.0,
1.0,1.0, 0.0,1.0, 0.0,0.0, 1.0,0.0,
1.0,0.0, 1.0,1.0, 0.0,1.0, 0.0,0.0,
}
tetrisMainData tetris
GLvoid Tetris_InitParam(void)
#ifdef _TETRIS_DEBUG
GLvoid tetris_debug(GLint t)
{
switch(t)
{
case 0:
break
case 1:
break
case 2:
break
}
}
#define debugSeg1() \
if(tetris.CurUnitsPos[0].col == tetris.CurUnitsPos[1].col\
&& tetris.CurUnitsPos[0].row == tetris.CurUnitsPos[1].row)\
tetris_debug(1)
#define debugSeg2()\
if(tetris.CurUnitsPos[0].row > TETRIS_ROW_NUMS+1\
|| tetris.CurUnitsPos[0].row < 0) tetris_debug(2)
if(tetris.CurUnitsPos[0].col > TETRIS_COL_NUMS - 1\
|| tetris.CurUnitsPos[0].col < 0) tetris_debug(2)
if(tetris.CurUnitsPos[1].row > TETRIS_ROW_NUMS+1\
|| tetris.CurUnitsPos[1].row < 0) tetris_debug(2)
if(tetris.CurUnitsPos[1].col > TETRIS_COL_NUMS - 1\
|| tetris.CurUnitsPos[1].col < 0) tetris_debug(2)
#define debugSeg3()\
if(fabs(tetris.CurUnitsPos[0].col - tetris.CurUnitsPos[1].col) > 2 \
|| fabs(tetris.CurUnitsPos[0].row - tetris.CurUnitsPos[1].row) > 2)\
tetris_debug(3)
#endif
//Read bitmap file data.
GLint ReadBMP(const char *filename, ImageRec *image) {
FILE *file
unsigned long size
unsigned long i
unsigned short int planes
unsigned short int bpp
char temp
if ((file = fopen(filename, "rb"))==NULL) {
printf("File Not Found : %s\n",filename)
return 0
}
fseek(file, 18, SEEK_CUR)
if ((i = fread(&image->sizeX, 4, 1, file)) != 1) {
printf("Error reading width from %s.\n", filename)
return 0
}
if ((i = fread(&image->sizeY, 4, 1, file)) != 1) {
printf("Error reading height from %s.\n", filename)
return 0
}
size = image->sizeX * image->sizeY * 3
if ((fread(&planes, 2, 1, file)) != 1) {
printf("Error reading planes from %s.\n", filename)
return 0
}
if (planes != 1) {
printf("Planes from %s is not 1: %u\n", filename, planes)
return 0
}
if ((i = fread(&bpp, 2, 1, file)) != 1) {
printf("Error reading bpp from %s.\n", filename)
return 0
}
if (bpp != 24) {
printf("Bpp from %s is not 24: %u\n", filename, bpp)
return 0
}
fseek(file, 24, SEEK_CUR)
image->data = (char *) malloc(size)
if (image->data == NULL) {
printf("Error allocating memory for color-corrected image data")
return 0
}
if ((i = fread(image->data, size, 1, file)) != 1) {
printf("Error reading image data from %s.\n", filename)
return 0
}
for (i=0
temp = image->data[i]
image->data[i] = image->data[i+2]
image->data[i+2] = temp
}
return 1
}
//Load texture of font which the game used.
GLboolean LoadBmpTextures(char *file,GLuint *texture)
{
int Status=0
ImageRec *TextureImage=NULL
TextureImage = (ImageRec*)malloc(sizeof(ImageRec))
memset(TextureImage,0,sizeof(ImageRec))
if (ReadBMP(file,TextureImage))
{
Status=1
glGenTextures(1, texture)
glBindTexture(GL_TEXTURE_2D, *texture)
glTexParameteri(GL_TEXTURE_2D,GL_TEXTURE_MAG_FILTER,GL_LINEAR)
glTexParameteri(GL_TEXTURE_2D,GL_TEXTURE_MIN_FILTER,GL_LINEAR)
glTexImage2D(GL_TEXTURE_2D, 0, 3, TextureImage->sizeX, TextureImage->sizeY, 0, GL_RGB, GL_UNSIGNED_BYTE, TextureImage->data)
}
if (TextureImage)
{
if (TextureImage->data)
{
free(TextureImage->data)
}
free(TextureImage)
}
return Status
}
//Create font display list.
GLvoid BuildFont(GLuint *texture)
{
float cx
float cy
tetris.fontBase=glGenLists(256)
glBindTexture(GL_TEXTURE_2D, (*texture))
for (GLint loop=0
{
cx=float(loop%16)/16.0f
cy=float(loop/16)/16.0f
glNewList(tetris.fontBase+loop,GL_COMPILE)
glBegin(GL_QUADS)
glTexCoord2f(cx,1-cy-0.0625f)
glVertex2i(0,0)
glTexCoord2f(cx+0.0625f,1-cy-0.0625f)
glVertex2i(32,0)
glTexCoord2f(cx+0.0625f,1-cy)
glVertex2i(32,32)
glTexCoord2f(cx,1-cy)
glVertex2i(0,32)
glEnd()
glTranslated(20,0,0)
glEndList()
}
}
//Delete the font
GLvoid KillFont(GLvoid)
{
glDeleteLists(tetris.fontBase,256)
}
//We can call the function below to display the content you want to...
GLvoid glPrint(GLint x, GLint y, char *string)
{
glBindTexture(GL_TEXTURE_2D, tetris.theTextures[TETRIS_TEXTURE_COUNT])
glPushMatrix()
glTranslated(x,y,0)
glListBase(tetris.fontBase)
glCallLists(strlen(string),GL_UNSIGNED_BYTE,string)
glPopMatrix()
}
//
void Texture_Adjust(GLubyte r, GLubyte g, GLubyte b, GLubyte absolute)
{
GLint width, height
glGetTexLevelParameteriv(GL_TEXTURE_2D, 0, GL_TEXTURE_WIDTH, &width)
glGetTexLevelParameteriv(GL_TEXTURE_2D, 0, GL_TEXTURE_HEIGHT, &height)
pixels = (GLubyte*)malloc(width*height*4)
if( pixels == 0 ) return
glGetTexImage(GL_TEXTURE_2D, 0, GL_BGRA_EXT, GL_UNSIGNED_BYTE, pixels)
{
GLint i
GLint count = width * height
for(i=0
{
if( abs(pixels[i*4] - b) <= absolute
&& abs(pixels[i*4+1] - g) <= absolute
&& abs(pixels[i*4+2] - r) <= absolute )
pixels[i*4+3] = 0
else
pixels[i*4+3] = 255
}
}
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, width, height, 0, GL_BGRA_EXT, GL_UNSIGNED_BYTE, pixels)
free(pixels)
}
//
void Texture_SetAlpha(GLubyte r, GLubyte g, GLubyte b,GLubyte absolute,GLubyte alpha)
{
GLint width, height
glGetTexLevelParameteriv(GL_TEXTURE_2D, 0, GL_TEXTURE_WIDTH, &width)
glGetTexLevelParameteriv(GL_TEXTURE_2D, 0, GL_TEXTURE_HEIGHT, &height)
pixels = (GLubyte*)malloc(width*height*4)
if( pixels == 0 ) return
glGetTexImage(GL_TEXTURE_2D, 0, GL_BGRA_EXT, GL_UNSIGNED_BYTE, pixels)
{
GLint i
GLint count = width * height
for(i=0
if( abs(pixels[i*4] - b) <= absolute
&& abs(pixels[i*4+1] - g) <= absolute
&& abs(pixels[i*4+2] - r) <= absolute )
pixels[i*4+3] = alpha
}
}
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, width, height, 0, GL_BGRA_EXT, GL_UNSIGNED_BYTE, pixels)
free(pixels)
}
//If the size of screen is changed,the function will be called.
//to readjust the screen param.
GLvoid changeWindow(GLsizei w, GLsizei h)
{
if (h == 0) h = 1
glViewport(0, 0, w, h)
glMatrixMode(GL_PROJECTION)
glLoadIdentity()
if (w <= h){
gluOrtho2D(0.0, TETRIS_SCREEN_WIDTH, 0.0, TETRIS_SCREEN_WIDTH * (GLfloat) h/(GLfloat) w)
glScalef(1.0,((float)h/TETRIS_SCREEN_HEIGHT)/((float)w/TETRIS_SCREEN_WIDTH),1.0)
}
else{
gluOrtho2D(0.0, TETRIS_SCREEN_HEIGHT * (GLfloat) w/(GLfloat) h, 0.0, TETRIS_SCREEN_HEIGHT)
glScalef(((float)w/TETRIS_SCREEN_WIDTH)/((float)h/TETRIS_SCREEN_HEIGHT),1.0,1.0)
}
glMatrixMode(GL_MODELVIEW)
glLoadIdentity()
}
//load all resource will be used.
GLvoid LoadGLTextures()
{
glPixelStorei(GL_UNPACK_ALIGNMENT, 1)
pngInfo info[4]
for (int k=0
glGenTextures(1,&tetris.theTextures[k])
tetris.theTextures[k] = pngBind(texturefiles[k], PNG_NOMIPMAP, PNG_ALPHA, &info[k], GL_CLAMP, GL_NEAREST, GL_NEAREST)
Texture_Adjust(255,255,255,10)
}
LoadBmpTextures("buchstabenalpha.bmp",&tetris.theTextures[TETRIS_TEXTURE_COUNT])
Texture_Adjust(0,0,0,11)
Texture_SetAlpha(133,133,133,122,128)
BuildFont(&tetris.theTextures[TETRIS_TEXTURE_COUNT])
}
//Draw a sprites
GLvoid render2Dsprite(GLint x,GLint y,GLint w,GLint h,GLint textureId,GLint angle=0)
{
const GLint (*p)[2]=TexCoord[angle]
glBindTexture(GL_TEXTURE_2D,textureId)
glBegin (GL_POLYGON)
glTexCoord2f(p[0][0], p[0][1])
glVertex2f (x, y)
glTexCoord2f(p[1][0], p[1][1])
glVertex2f (x+w, y)
glTexCoord2f(p[2][0], p[2][1])
glVertex2f (x+w, y+h)
glTexCoord2f(p[3][0], p[3][1])
glVertex2f (x, y+h)
glEnd ()
}
//Draw the scene of the game.
GLvoid render()
{
glutSetWindow(tetris.mainWindow)
glClearColor(0.0, 0.0, 0.0, 1.0)
glClear (GL_COLOR_BUFFER_BIT)
glLoadIdentity()
glPushMatrix()
char str[32]
glPushMatrix()
glEnable (GL_BLEND)
glLoadIdentity()
str[0] = '\0'
strcpy(str,"Tetris")
glTranslatef(0.0,TETRIS_SCREEN_HEIGHT/2,0.0)
glScalef(3.2,3.2,1.0)
glPrint(0.0,0.0,str)
glDisable(GL_BLEND)
glPopMatrix()
glPushMatrix()
if(tetris.gameover){
if(tetris.gamecount>>4&1){
glTranslatef(30,TETRIS_SCREEN_HEIGHT/2.0,0.0)
glScalef(1.5,1.5,1.0)
glPrint(0.0,0.0,"Game Over!")
}
}
if(tetris.levelStart==1){
if(tetris.gamecount>>4&1){
glTranslatef(50,TETRIS_SCREEN_HEIGHT/2.0,0.0)
str[0] = '\0'
sprintf(str,"Level %d",tetris.level)
glScalef(2.0,2.0,1.0)
glPrint(0.0,0.0,str)
}
}
if(tetris.levelStart == 2)
{
if(tetris.gamecount>>4&1){
glTranslatef(20.0,TETRIS_SCREEN_HEIGHT/2.0+tetris.waitUserTextSy,0.0)
glScalef(0.8,0.8,1.0)
glPrint(0.0,0.0,"Press Enter to replay.")
}
if(tetris.waitUserTextSydir){
tetris.waitUserTextSy += 2
if(tetris.waitUserTextSy > TETRIS_SCREEN_HEIGHT/2 - 32)
tetris.waitUserTextSydir = 0
}else{
tetris.waitUserTextSy -= 2
if(tetris.waitUserTextSy < -(TETRIS_SCREEN_HEIGHT/2 - 32))
tetris.waitUserTextSydir = 1
}
}
if(tetris.updateLevel)
{
tetris.updateLevel--
if(tetris.updateLevel>TETRIS_DELAY_TIME){
if(tetris.gamecount>>4&1){
glTranslatef(35.0,TETRIS_SCREEN_HEIGHT/2.0,0.0)
glScalef(0.8,0.8,1.0)
glPrint(0.0,0.0,"Congratulation!")
glTranslatef(-15.0,-20.0,0.0)
glPrint(0.0,0.0,"Level updating!")
}
}else{
if(tetris.gamecount>>4&1){
glTranslatef(50,TETRIS_SCREEN_HEIGHT/2.0,0.0)
str[0] = '\0'
sprintf(str,"Level %d",tetris.level)
glScalef(2.0,2.0,1.0)
glPrint(0.0,0.0,str)
}
}
}
glPopMatrix()
unitData *p=tetris.units,*pTemp
for(int j=0
for(int i=0
pTemp = &p[j*TETRIS_COL_NUMS+i]
if(pTemp->fill){
glPushMatrix()
render2Dsprite(i*TETRIS_UNIT_WIDTH,j*TETRIS_UNIT_HEIGHT,TETRIS_UNIT_WIDTH,TETRIS_UNIT_HEIGHT,tetris.theTextures[pTemp->color],pTemp->angle)
glPopMatrix()
}
}
}
glPushMatrix()
glEnable (GL_BLEND)
glDisable(GL_ALPHA_TEST)
glLoadIdentity()
glTranslatef(0.0,TETRIS_SCREEN_HEIGHT-32,0.0)
glPushMatrix()
str[0] = '\0'
glScalef(0.8,0.8,1.0)
sprintf(str,"Score:%d",tetris.score)
glPrint(0.0,0.0,str)
glPopMatrix()
glTranslatef(TETRIS_SCREEN_WIDTH*2/3,0.0,0.0)
glPushMatrix()
str[0] = '\0'
glScalef(0.8,0.8,1.0)
sprintf(str,"Level:%d",tetris.level)
glPrint(0.0,0.0,str)
glPopMatrix()
glTranslatef(-TETRIS_SCREEN_WIDTH*2/3,-20.0,0.0)
glPushMatrix()
glScalef(0.7,0.7,1.0)
glPrint(0.0,0.0,"Press Space to pause.")
glTranslatef(0.0,-20.0,0.0)
glPrint(0.0,0.0,"Press Esc to exit.")
glPopMatrix()
glDisable(GL_BLEND)
glEnable (GL_ALPHA_TEST)
glPopMatrix()
glEnd ()
glPopMatrix()
glutSwapBuffers()
}
GLvoid Tetris_SetSingleUnit(unitData *p,GLint color,GLint angle)
{
p->fill = 1
}
//Rotate the object.
GLvoid Tetris_TwoUnitRotate()
{
if(tetris.CurUnitsStat != 1) return
unitData *pDest=NULL,*pMid=NULL,*pTemp
unitData (*pa)[TETRIS_COL_NUMS]=(unitData (*)[TETRIS_COL_NUMS])tetris.units
pTemp = &pa[tetris.CurUnitsPos[0].row][tetris.CurUnitsPos[0].col]
if(tetris.CurUnitsPos[1].col == tetris.CurUnitsPos[0].col){
if(tetris.CurUnitsPos[1].row < tetris.CurUnitsPos[0].row){
if(tetris.CurUnitsPos[1].col == TETRIS_COL_NUMS - 1) return
pMid = pTemp - TETRIS_COL_NUMS + 1
pDest = pTemp + 1
}else if(tetris.CurUnitsPos[1].row > tetris.CurUnitsPos[0].row){
if(tetris.CurUnitsPos[1].col == 0) return
pMid = pTemp + TETRIS_COL_NUMS - 1
pDest = pTemp - 1
}else{
#ifdef _TETRIS_DEBUG
tetris_debug(0)
#endif
}
}else if(tetris.CurUnitsPos[1].row == tetris.CurUnitsPos[0].row){
if(tetris.CurUnitsPos[1].col < tetris.CurUnitsPos[0].col){
if(tetris.CurUnitsPos[1].row == 0) return
pMid = pTemp - TETRIS_COL_NUMS - 1
pDest = pTemp - TETRIS_COL_NUMS
}else if(tetris.CurUnitsPos[1].col > tetris.CurUnitsPos[0].col){
pMid = pTemp + TETRIS_COL_NUMS + 1
pDest = pTemp + TETRIS_COL_NUMS
}else{
#ifdef _TETRIS_DEBUG
tetris_debug(0)
#endif
}
}else {
#ifdef _TETRIS_DEBUG
tetris_debug(0)
#endif
}
if(NULL == pDest || NULL == pMid) return
if(pDest->fill || pMid->fill) return
pa[tetris.CurUnitsPos[1].row][tetris.CurUnitsPos[1].col].fill = 0
tetris.CurUnitsPos[1].col = (pDest - tetris.units) % TETRIS_COL_NUMS
tetris.CurUnitsPos[1].row = (pDest - tetris.units) / TETRIS_COL_NUMS
tetris.CurUnits[1].angle = (tetris.CurUnits[1].angle+1)%4
tetris.CurUnits[0].angle = (tetris.CurUnits[0].angle+1)%4
pa[tetris.CurUnitsPos[0].row][tetris.CurUnitsPos[0].col].angle = tetris.CurUnits[0].angle
Tetris_SetSingleUnit(pDest,tetris.CurUnits[1].color,tetris.CurUnits[1].angle)
}
//Call back function about keyboard.
GLvoid keys(unsigned char key, GLint x, GLint y)
{
if(key == TETRIS_KEY_ESCAPE) exit(0)
if(key == TETRIS_KEY_SPACE) { tetris.gamepause = (++tetris.gamepause)%2
if(key == TETRIS_KEY_ENTER) {
tetris.levelStart = 0
tetris.delay = TETRIS_DELAY_TIME
Tetris_InitParam()
}
if(tetris.CurUnitsStat != 1) return
if(tetris.gamepause) return
if(tetris.levelStart) return
if(tetris.gameover) return
unitData (*pa)[TETRIS_COL_NUMS]=(unitData (*)[TETRIS_COL_NUMS])tetris.units
unitData *pUnitTemp[2]
GLint i,j,k
for(i=0
pUnitTemp[i] = &pa[tetris.CurUnitsPos[i].row][tetris.CurUnitsPos[i].col]
switch(key)
{
case TETRIS_KEY_SPACE:
break
case TETRIS_KEY_UP:
Tetris_TwoUnitRotate()
break
case TETRIS_KEY_DOWN:
tetris.frequency = TETRIS_FREQUENCY_MIN
break
case TETRIS_KEY_LEFT:
j = tetris.CurUnitsPos[0].col <= tetris.CurUnitsPos[1].col
for(k=0
if(j == 0) i = (k+1)%2
else i = k
if(tetris.CurUnits[i].stat) continue
if(tetris.CurUnitsPos[i].col > 0
&& !(pUnitTemp[i]-1)->fill){
tetris.CurUnitsPos[i].col--
pUnitTemp[i]->fill = 0
Tetris_SetSingleUnit(pUnitTemp[i]-1,tetris.CurUnits[i].color,tetris.CurUnits[i].angle)
}
}
break
case TETRIS_KEY_RIGHT:
j = tetris.CurUnitsPos[0].col >= tetris.CurUnitsPos[1].col
for(k=0
if(j == 0) i = (k+1)%2
else i = k
if(tetris.CurUnits[i].stat) continue
if(tetris.CurUnitsPos[i].col < TETRIS_COL_NUMS - 1
&& !(pUnitTemp[i]+1)->fill){
tetris.CurUnitsPos[i].col++
pUnitTemp[i]->fill = 0
Tetris_SetSingleUnit(pUnitTemp[i]+1,tetris.CurUnits[i].color,tetris.CurUnits[i].angle)
}
}
break
}
glutPostRedisplay()
}
GLvoid specialKeysPressed(GLint key, GLint x, GLint y)
{
switch(key)
{
case GLUT_KEY_UP:
keys(TETRIS_KEY_UP,0,0)
break
case GLUT_KEY_DOWN:
keys(TETRIS_KEY_DOWN,0,0)
break
case GLUT_KEY_LEFT:
keys(TETRIS_KEY_LEFT,0,0)
break
case GLUT_KEY_RIGHT:
keys(TETRIS_KEY_RIGHT,0,0)
break
}
}
GLvoid Tetris_InitMem(void*start,GLint size)
{
GLbyte *p=(GLbyte*)start
while(size--) (*p) = 0
}
GLvoid Tetris_InitTwoUnits(unitData*p)
{
GLint tmp=rand()%3
switch(tmp)
{
case 0:
tmp = TETRIS_COL_NUMS / 2 - 1
tetris.CurUnitsPos[0].col = tmp
tetris.CurUnitsPos[1].col = tmp+1
tetris.CurUnitsPos[0].row = TETRIS_ROW_NUMS
tetris.CurUnitsPos[1].row = TETRIS_ROW_NUMS
break
case 1:
tmp = TETRIS_COL_NUMS / 2 - 1
tetris.CurUnitsPos[0].col = tmp
tetris.CurUnitsPos[1].col = tmp
tetris.CurUnitsPos[0].row = TETRIS_ROW_NUMS
tetris.CurUnitsPos[1].row = TETRIS_ROW_NUMS+1
break
case 2:
tmp = TETRIS_COL_NUMS / 2
tetris.CurUnitsPos[0].col = tmp
tetris.CurUnitsPos[1].col = tmp
tetris.CurUnitsPos[0].row = TETRIS_ROW_NUMS
tetris.CurUnitsPos[1].row = TETRIS_ROW_NUMS+1
break
}
Tetris_InitMem(&p[0],sizeof(unitData))
p[0].color = rand()%4
Tetris_InitMem(&p[1],sizeof(unitData))
p[1].color = rand()%4
tetris.CurUnitsStat = 1
}
GLvoid Tetris_GameOver()
{
memset(tetris.units,0,sizeof(tetris.units))
tetris.pool.clear()
tetris.poolex.clear()
}
//
GLboolean Tetris_TwoUnitsFunc(unitData *p)
{
unitData (*pa)[TETRIS_COL_NUMS]=(unitData (*)[TETRIS_COL_NUMS])tetris.units
unitData *pUnitTemp[2],*ps
GLint i,j,k,cnt
for(i=0
pUnitTemp[i] = &pa[tetris.CurUnitsPos[i].row][tetris.CurUnitsPos[i].col]
if(tetris.gamecount % tetris.frequency){ return 0
else{
j = (tetris.CurUnitsPos[0].row <= tetris.CurUnitsPos[1].row)
cnt = 0
for(k=0
if(j == 0) i = (k+1)%2
else i = k
if(0 != p[i].stat)
continue
cnt++
ps = pUnitTemp[i] - TETRIS_COL_NUMS
if(ps >= tetris.units){
if(ps->fill < 2){
if(--tetris.CurUnitsPos[i].row < 0)
tetris.CurUnitsPos[i].row = 0
Tetris_SetSingleUnit(ps,p[i].color,p[i].angle)
pUnitTemp[i]->fill = 0
}else {
if(ps < &tetris.units[TETRIS_UNITS_NUM])
{
pUnitTemp[i]->fill = 2
if(pUnitTemp[i] > &tetris.units[TETRIS_UNITS_NUM] - TETRIS_COL_NUMS )
{
tetris.gameover = 1
tetris.delay = TETRIS_DELAY_TIME*2
Tetris_GameOver()
return 1
}
}
p[i].stat = 1
}
}else{
p[i].stat = 1
pUnitTemp[i]->fill = 2
}
}
if(0 == cnt) tetris.CurUnitsStat = 2
tetris.updating = 1
tetris.pool.clear()
tetris.pool.push_back(&pa[tetris.CurUnitsPos[0].row][tetris.CurUnitsPos[0].col])
tetris.pool.push_back(&pa[tetris.CurUnitsPos[1].row][tetris.CurUnitsPos[1].col])
}
return 1
}
GLvoid Tetris_Update()
{
GLint i,j,cnt=0
unitData (*pa)[TETRIS_COL_NUMS]=(unitData (*)[TETRIS_COL_NUMS])tetris.units
list<unitData*> *pool
list<unitData*>::iterator iter
GLint col,row
pool = &tetris.poolex
for(cnt=0,iter=pool->begin()
{
unitData *p,*q
p = q = (*iter)
i = 0
p += TETRIS_COL_NUMS
while(p < &tetris.units[TETRIS_UNITS_NUM] && p->fill) { i++
if(i > 0)
{
p = (*iter)
p -= TETRIS_COL_NUMS
while(p >= tetris.units && !p->fill) {p -= TETRIS_COL_NUMS
tetris.pool.push_back(p+TETRIS_COL_NUMS)
j = 0
while(j++ < i){
p += TETRIS_COL_NUMS
q += TETRIS_COL_NUMS
(*p)=(*q)
p->fill = 2
q->fill = 0
}
cnt++
}
}
if(pool->size() > 0) pool->clear()
if(cnt) return
pool = &tetris.pool
for(cnt = 0,iter=pool->begin()
{
unitData *p,*pthis
GLint nums[4]={0},num=0
GLint thiscol,thisrow,index
p = pthis = (*iter)
index = p - tetris.units
thiscol = index % TETRIS_COL_NUMS
thisrow = index / TETRIS_COL_NUMS
//bottom
i = 0
row = thisrow - 1
col = thiscol
p = &pa[row][col]
while(row >= 0 && p->fill && p->color == pthis->color) { nums[0]++
//left
i = 0
row = thisrow
col = thiscol - 1
p = &pa[row][col]
while(col >= 0 && p->fill && p->color == pthis->color) { nums[1]++
//right
i = 0
row = thisrow
col = thiscol + 1
p = &pa[row][col]
while(col < TETRIS_COL_NUMS && p->fill && p->color == pthis->color) { nums[2]++
//above
i = 0
row = thisrow + 1
col = thiscol
p = &pa[row][col]
while(row < TETRIS_ROW_NUMS && p->fill && p->color == pthis->color) {
nums[3]++
}
num = nums[0] + nums[3] + 1
if(num >= 4){
p = pthis - nums[0] * TETRIS_COL_NUMS
for(i = 0
p->fill = 0
p += TETRIS_COL_NUMS
}
tetris.score += 5*num
p = p-TETRIS_COL_NUMS
unitPos *pos=tetris.CurUnitsPos
if(p == &pa[pos[0].row][pos[0].col]
|| p == &pa[pos[0].row][pos[0].col]){}
else{
tetris.poolex.push_back(p)
cnt++
}
}
num = nums[1] + nums[2] + 1
if(num >= 4){
p = pthis - nums[1]
for(i = 0
tetris.poolex.push_back(p)
p->fill = 0
p++
}
tetris.score += 5*num
cnt++
}
}
if((tetris.score - tetris.scoreLastLevel) > 50 + (tetris.level) * 10){
tetris.updateLevel = 128
tetris.level++
tetris.scoreLastLevel = tetris.score
tetris.frequencymax -= 2
if(tetris.frequencymax < 1) tetris.frequencymax = 1
}
if(0 == cnt) {
tetris.updating = 0
for(i = 0
if(!pa[tetris.CurUnitsPos[i].row][tetris.CurUnitsPos[i].col].fill)
tetris.CurUnits[i].stat = 1
}
else tetris.updating++
}
//Timer,
GLvoid OnTimer(int time)
{
unitData *p=tetris.CurUnits
GLboolean flag=0
if(++tetris.gamecount == 30000)
tetris.gamecount = 0
if(tetris.gamepause
||tetris.gameover
|| tetris.levelStart
|| tetris.delay)
{
glutTimerFunc(5, OnTimer, 1)
glutPostRedisplay()
if(tetris.delay > 0){
tetris.delay--
if(tetris.delay == 0){
if(tetris.levelStart==1){
tetris.levelStart = 0
//tetris.gameover = 1
//tetris.delay = TETRIS_DELAY_TIME
//tetris.levelStart = 2
return
}
if(tetris.gameover){
tetris.gameover = 0
tetris.levelStart = 2
tetris.waitUserTextSy = 0
return
}
}
}
return
}
switch(tetris.CurUnitsStat)
{
case 0:
Tetris_InitTwoUnits(p)
break
case 1:
if(!tetris.updating)
flag = Tetris_TwoUnitsFunc(p)
break
case 2:
tetris.CurUnitsStat = 0
break
}
glutPostRedisplay()
glutTimerFunc(5, OnTimer, 1)
if(!flag && tetris.updating)
Tetris_Update()
tetris.frequency = tetris.frequencymax
}
GLvoid idle()
{
}
GLvoid Tetris_InitParam(void)
{
tetris.level = 1
tetris.score = 0
tetris.levelStart = 1
tetris.frequencymax = TETRIS_FREQUENCY_MAX
tetris.frequency = tetris.frequencymax
tetris.delay = TETRIS_DELAY_TIME
tetris.CurUnitsStat = 0
memset(tetris.CurUnits,0,sizeof(tetris.CurUnits))
memset(tetris.CurUnitsPos,0,sizeof(tetris.CurUnitsPos))
memset(tetris.units,0,sizeof(tetris.units))
tetris.scoreLastLevel = 0
}
//Init game.
GLvoid initgame()
{
LoadGLTextures()
glEnable(GL_TEXTURE_2D)
glAlphaFunc(GL_GREATER, 0.1f)
glEnable (GL_BLEND)
glBlendFunc (GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA)
glShadeModel (GL_FLAT)
Tetris_InitParam()
}
GLint main(GLint argc,char** argv)
{
glutInit(&argc, argv)
glutInitDisplayMode(GLUT_DOUBLE | GLUT_RGBA)
glutInitWindowPosition(100,100)
glutInitWindowSize(TETRIS_SCREEN_WIDTH,TETRIS_SCREEN_HEIGHT)
tetris.mainWindow = glutCreateWindow(appName)
glutReshapeFunc(changeWindow)
glutDisplayFunc(render)
glutKeyboardFunc(keys)
glutSpecialFunc(specialKeysPressed)
glutSetCursor(GLUT_CURSOR_NONE)
glutTimerFunc(5,OnTimer,1)
glutIdleFunc(idle)
initgame()
glutMainLoop()
return 0
}